【转载】正则表达式不会用?记不住?10分钟动手全部搞懂
文章出处
正文开始
正则表达式对于我们来说既熟悉又陌生,我们在很多时候都遇到过,但是学起来又很难记,不好理解;在没有接触正则表达式的时候,我就在想这一串奇怪的字符为啥可以代替其他很长的一段代码就可以得到预期值,去网上找资料和技术文章学习的时候,发现有很多知识点晦涩难懂;下面我将用非常通俗易懂的方法和大家一起学习正则表达式。
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
首先我们要在网页编译器 regular expression 101 在线编译里自己动手跟着操作一遍就会发现其实没有那么难理解。(一定要实际动手操作加深记忆)
一、基础字符
接下来一起操作一遍:(默认选中颜色表示符合条件)
1. +号表示前边的字符必须至少出现一次(1次或多次);
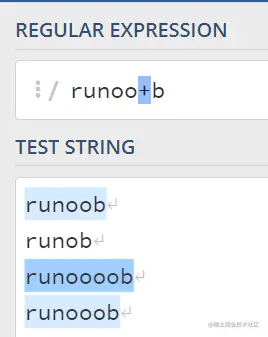
2.* 表示前边的字符可以不出现,或者出现一次或者多次(0次、或1次、或多次)
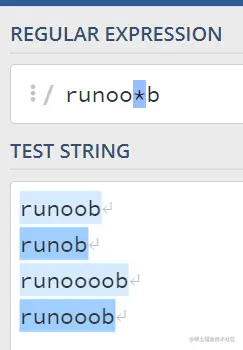
3.?号表示前面的字符最多只可以出现一次(0次或1次)
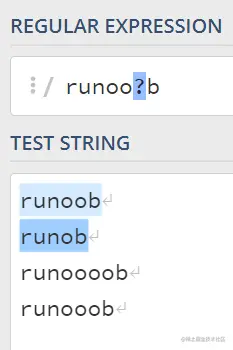
4.{}号:
还是上边的例子
比如希望{}前面的字符出现的次数是4次,就用{4}表示
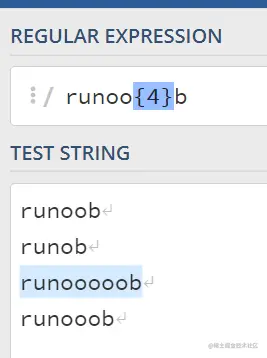
{} 还可以允许我们输入一个范围;比如{2,4}表示前一个字符出现2到4次;
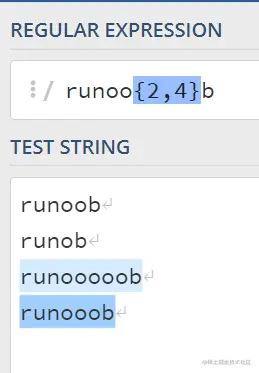
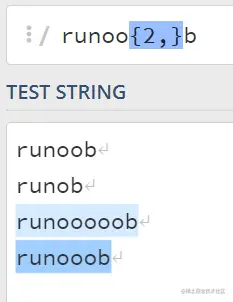
如果想表示出现2次以上;就用{2,}表示;
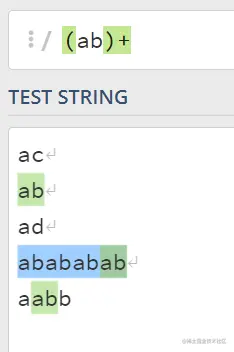
5.如果想查找多个字符就()+
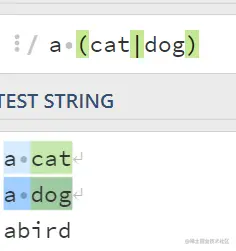
6.“或” 通配符 如果想找 a dog和a cat就在()里加“|”;这里前面会先区匹配“a”
7.字符类[]+可以匹配中括号里的字符,匹配到的字符只能取自于它们
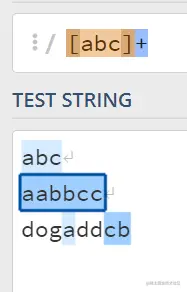
另外 []+ 可以匹配字符的范围
[a-z]+ 表示匹配所有的小写英文字母;[A-Z]+ 表示匹配所有的大写英文字母;
[a-zA-Z]+ 表示匹配所有的英文字符;[a-zA-Z0-9]+ 表示所有的英文字符和数字
8.如果在 []+ 前边加 ^ ,就表示匹配除了尖号后边列出的【以外】的字符(包括换行符)
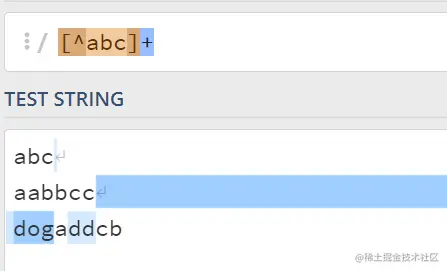
二、一系列常用的字符;
1、一些元字符(Meta-characters)
比如数字、空白符、单词开头、结尾等等它们被称为元字符;
\d \w \s \D \W \S … 正则表达式的大多数元字符都以反斜杠开头;
1)\d 是数字字符,等同于之前写的 [0-9]+;

2)\w 代表单词字符(英文、数字及下划线)

3)\s 代表空白符 (包含Tab和换行符)

4)与 \d 相对应的 \D 代表非数字字符

5) 与 \w 相对应的 \W 代表非单词字符

6) 与 \s 相对应的 \S 代表非空白字符

2. 其中 . 在正则表达式中也是一个特殊字符;它代表任意字符,但不包含换行字符。

3.两个特殊字符 ^ 匹配行首、$ 匹配行尾;


三、一些高级概念
1、贪婪与懒惰匹配
之前学到 * + {} 在匹配字符串的时候默认会去匹配尽可能多的字符
比如我们需要匹配下边的html标签;我们 最开始想到的肯定是 <.+>来匹配;

但是这么会把全部字符和标签选中,因为 . 表示任意字符,+ 号又表示前一项可以出现多次;不是我们想要的标签匹配,那么我们该怎么办呢?其实只需要在+号右边加一个 ?就好了。
它会将正则表达式中默认的贪婪匹配(Greedy Math)切换为懒惰匹配(Lazy Match)
我们来试一下:

2、两个实例加深理解
1.颜色值的匹配:RGBS值
因为RGM码是由#和6位十六进制字符组成;
首先要匹配,颜色匹配符前边的#号;因为RGM是十六进制的,所以只能取自a-f和A-F和0-9之间; 并且长度一定是6位,最后\b作为边界值,避免不是RGM颜色的代码被识别。 一起在编译器里看一下:
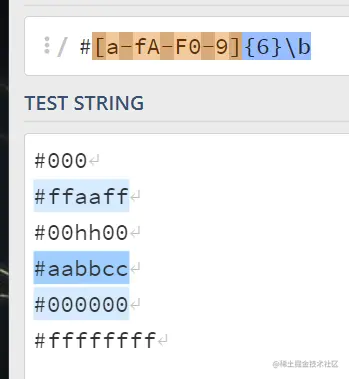
可以得到预期匹配值。
2.ipv4 地址匹配
其实Ipv4地址是由四段代码实现的,数字之间由句号隔开;如果要在文本中提取所有出现的ip地址
可以直接使用\d+\.d+\.d+\.d+来进行匹配;
思路1)首先\d+ 会匹配所有的数字;
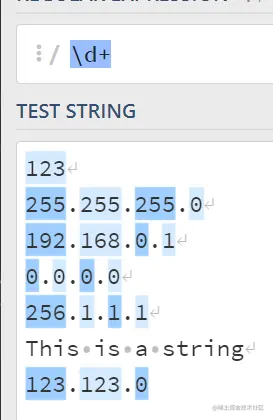
这里可以看到成功的匹配到了ipv4地址;
但是还存在一个问题;ip地址都是八位的,也就是它的范围介于0-255之间
但是256很明显超出了范围,但是还是被匹配了。
2)这时候就需要换一种思路:
首先匹配25,然后第二位取[0-5]之间的数字 : 25[0-5];
其次如果它的第一个字母是2,第二个字母是[0-4]之间的,最后一位可以取0-9之间的任意值用 \d表示 : 2[0-4]\d;
如果第一位是[01],那么最后两位可以取00-99之间的任意数字这里用\d\d表示:[01]\d\d
这三种情况中间用 | 号连接;
但是有时候,IP地址每一段也可以是两位数字甚至一位数字,这时候就可以直接在后两位数字后边加 ?来表示。这时候数字部分就匹配完成:25[0-5]|2[0-4]\d|[01]?\d\d?
我们需要匹配三次 ((25[0-5]|2[0-4]\d|[01]?\d\d?)\.){3};把前三段数字和后边的句点匹配完毕;
然后后边的代码还需要重复前边三段的代码 ;最后需要在收尾都加入 \ b 来匹配字符的边界;
然后看一下完整代码:
1 | \b((25[0-5]|2[0-4]\d|[01]?\d\d?)\.){3}(25[0-5]|2[0-4]\d|[01]?\d\d?)\b |
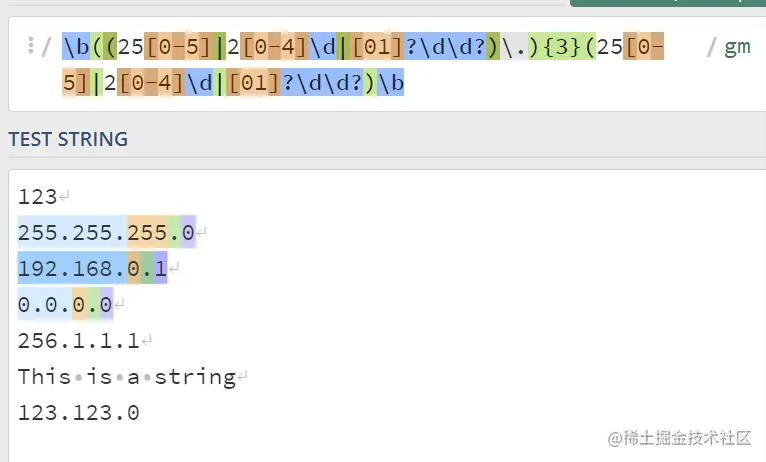
这里看出我们已经可以匹配到预期的完整字符。
四、正则表达式常用语法
1.Flags(标志符或修饰符)
g:全局匹配(global);正则表达式默认只会返回第一个匹配结果,使用标志符g则可以返回所有匹配
i:忽略大小写(case-insensitive);在匹配时忽略英文字母的大小写
m:多行匹配(multiline);将开始和结束字符(^和$)视为在多行上工作,即分别匹配每一行(由 \n 或 \r 分割)的开始和结束,而不只是只匹配整个输入字符串的最开始和最末尾处
2. Character Sets(字符集合)
用于匹配字符集合中的任意一个字符,常见的字符集有:
[xyz]:匹配 “x”或”y”``”z”
[^xyz]:补集,匹配除 “x” “y” “z”的其他字符
[a-z]:匹配从 “a” 到 “z” 的任意字符
[^a-n]:补集,匹配除 “a” 到 “n” 的其他字符
[A-Z]:匹配从 “A” 到 “Z” 的任意字符
[0-9]:匹配从 “0” 到 “9” 的任意数字
比如匹配所有的字母和数字可以写成:/[a-zA-Z0-9]/ 或者 /[a-z0-9]/i。
3. Quantifiers (量词)
在实际使用中常需要匹配同一类型的字符多次,比如匹配 11 位的手机号,我们不可能将 [0-9] 写 11 遍,此时可以使用 Quantifiers 来实现重复匹配。
{n}:匹配 n 次
{n,m}:匹配 n-m 次
{n,}:匹配 >=n 次
?:匹配 0 || 1 次
*:匹配 >=0 次,等价于 {0,}
+:匹配 >=1 次,等价于 {1,}
4. Metacharacters(元字符)
常见的元字符有:
\d:匹配任意数字,等价于 [0-9]
\D:匹配任意非数字字符;\d 的补集
\w:匹配任意基本拉丁字母表中的字母和数字,以及下划线;等价于 [A-Za-z0-9_]
\W:匹配任意非基本拉丁字母表中的字母和数字,以及下划线;\w 的补集
\s:匹配一个空白符,包括空格、制表符、换页符、换行符和其他 Unicode 空格
\S:匹配一个非空白符;\s的补集
\b:匹配一个零宽单词边界,如一个字母与一个空格之间;例如,/\bno/ 匹配 “at noon” 中的 “no”,/ly\b/ 匹配 “possibly yesterday.” 中的 “ly”
\B:匹配一个零宽非单词边界,如两个字母之间或两个空格之间;例如,/\Bon/ 匹配 “at noon” 中的 “on”,/ye\B/ 匹配 “possibly yesterday.”中的 “ye”
\t:匹配一个水平制表符(tab)
\n:匹配一个换行符(newline)
\r:匹配一个回车符(carriage return)
5.贪婪/懒惰匹配(Greedy/Lazy Match)
<.+>: 默认贪婪匹配“任意字符”; <.+?>: 懒惰匹配“任意字符”;
总结:其实正则表达式还有许多高级概念,如果大家想深入学习: 我推荐大家可以看一下这个视频和文章:(目前也在学习)
好啦其实就是分享一些很基础的东西,技术有限。欢迎大家一起讨论学习。